执行上下文
当执行 JS 代码时,会产生三种执行上下文
- 全局执行上下文
- 函数执行上下文
- eval 执行上下文
每个执行上下文中都有三个重要的属性
- 变量对象(VO),包含变量、函数声明和函数的形参,该属性只能在全局上下文中访问
- 作用域链(JS 采用词法作用域,也就是说变量的作用域是在定义时就决定了)
- this
var a = 10 function foo(i) { var b = 20 } foo()
对于上述代码,执行栈中有两个上下文:全局上下文和函数 foo 上下文。
stack = [ globalContext, fooContext ]
对于全局上下文来说,VO 大概是这样的
globalContext.VO === globe globalContext.VO = { a: undefined, foo: <Function>, }
对于函数 foo 来说,VO 不能访问,只能访问到活动对象(AO)
fooContext.VO === foo.AO fooContext.AO { i: undefined, b: undefined, arguments: <> } // arguments 是函数独有的对象(箭头函数没有) // 该对象是一个伪数组,有 `length` 属性且可以通过下标访问元素 // 该对象中的 `callee` 属性代表函数本身 // `caller` 属性代表函数的调用者
对于作用域链,可以把它理解成包含自身变量对象和上级变量对象的列表,通过 [[Scope]] 属性查找上级变量
fooContext.[[Scope]] = [ globalContext.VO ] fooContext.Scope = fooContext.[[Scope]] + fooContext.VO fooContext.Scope = [ fooContext.VO, globalContext.VO ]
接下来让我们看一个老生常谈的例子,var
b() // call b console.log(a) // undefined var a = 'Hello world' function b() { console.log('call b') }
想必以上的输出大家肯定都已经明白了,这是因为函数和变量提升的原因。通常提升的解释是说将声明的代码移动到了顶部,这其实没有什么错误,便于大家理解。但是更准确的解释应该是:在生成执行上下文时,会有两个阶段。第一个阶段是创建的阶段(具体步骤是创建 VO),JS 解释器会找出需要提升的变量和函数,并且给他们提前在内存中开辟好空间,函数的话会将整个函数存入内存中,变量只声明并且赋值为 undefined,所以在第二个阶段,也就是代码执行阶段,我们可以直接提前使用。
在提升的过程中,相同的函数会覆盖上一个函数,并且函数优先于变量提升
b() // call b second function b() { console.log('call b fist') } function b() { console.log('call b second') } var b = 'Hello world'
var 会产生很多错误,所以在 ES6中引入了 let。let 不能在声明前使用,但是这并不是常说的 let 不会提升,let 提升了声明但没有赋值,因为临时死区导致了并不能在声明前使用。
对于非匿名的立即执行函数需要注意以下一点
var foo = 1 (function foo() { foo = 10 console.log(foo) }()) // -> ƒ foo() { foo = 10 ; console.log(foo) }
因为当 JS 解释器在遇到非匿名的立即执行函数时,会创建一个辅助的特定对象,然后将函数名称作为这个对象的属性,因此函数内部才可以访问到 foo,但是这个值又是只读的,所以对它的赋值并不生效,所以打印的结果还是这个函数,并且外部的值也没有发生更改。
specialObject = {}; Scope = specialObject + Scope; foo = new FunctionExpression; foo.[[Scope]] = Scope; specialObject.foo = foo; // {DontDelete}, {ReadOnly} delete Scope[0]; // remove specialObject from the front of scope chain
Javascript中的this
this 是很多人会混淆的概念,但是其实他一点都不难,你只需要记住几个规则就可以了。
function foo() { console.log(this.a) } var a = 1 foo() var obj = { a: 2, foo: foo } obj.foo() // 以上两者情况 `this` 只依赖于调用函数前的对象,优先级是第二个情况大于第一个情况 // 以下情况是优先级最高的,`this` 只会绑定在 `c` 上,不会被任何方式修改 `this` 指向 var c = new foo() c.a = 3 console.log(c.a) // 还有种就是利用 call,apply,bind 改变 this,这个优先级仅次于 new
以上几种情况明白了,很多代码中的 this 应该就没什么问题了,下面让我们看看箭头函数中的 this
function a() { return () => { return () => { console.log(this) } } } console.log(a()()())
箭头函数其实是没有 this 的,这个函数中的 this 只取决于他外面的第一个不是箭头函数的函数的 this。在这个例子中,因为调用 a 符合前面代码中的第一个情况,所以 this 是 window。并且 this 一旦绑定了上下文,就不会被任何代码改变。
instanceof
instanceof 可以正确的判断对象的类型,因为内部机制是通过判断对象的原型链中是不是能找到类型的 prototype。
我们也可以试着实现一下 instanceof
function instanceof(left, right) { // 获得类型的原型 let prototype = right.prototype // 获得对象的原型 left = left.__proto__ // 判断对象的类型是否等于类型的原型 while (true) { if (left === null) return false if (prototype === left) return true left = left.__proto__ } }
new
- 新生成了一个对象
- 链接到原型
- 绑定 this
- 返回新对象
在调用 new 的过程中会发生以上四件事情,我们也可以试着来自己实现一个 new
function create() { // 创建一个空的对象 let obj = new Object() // 获得构造函数 let Con = [].shift.call(arguments) // 链接到原型 obj.__proto__ = Con.prototype // 绑定 this,执行构造函数 let result = Con.apply(obj, arguments) // 确保 new 出来的是个对象 return typeof result === 'object' ? result : obj }
对于实例对象来说,都是通过 new 产生的,无论是 function Foo() 还是 let a = { b : 1 } 。
对于创建一个对象来说,更推荐使用字面量的方式创建对象(无论性能上还是可读性)。因为你使用 new Object() 的方式创建对象需要通过作用域链一层层找到 Object,但是你使用字面量的方式就没这个问题。
function Foo() {} // function 就是个语法糖 // 内部等同于 new Function() let a = { b: 1 } // 这个字面量内部也是使用了 new Object()
对于 new 来说,还需要注意下运算符优先级。
function Foo() { return this; } Foo.getName = function () { console.log('1'); }; Foo.prototype.getName = function () { console.log('2'); }; new Foo.getName(); // -> 1 new Foo().getName(); // -> 2
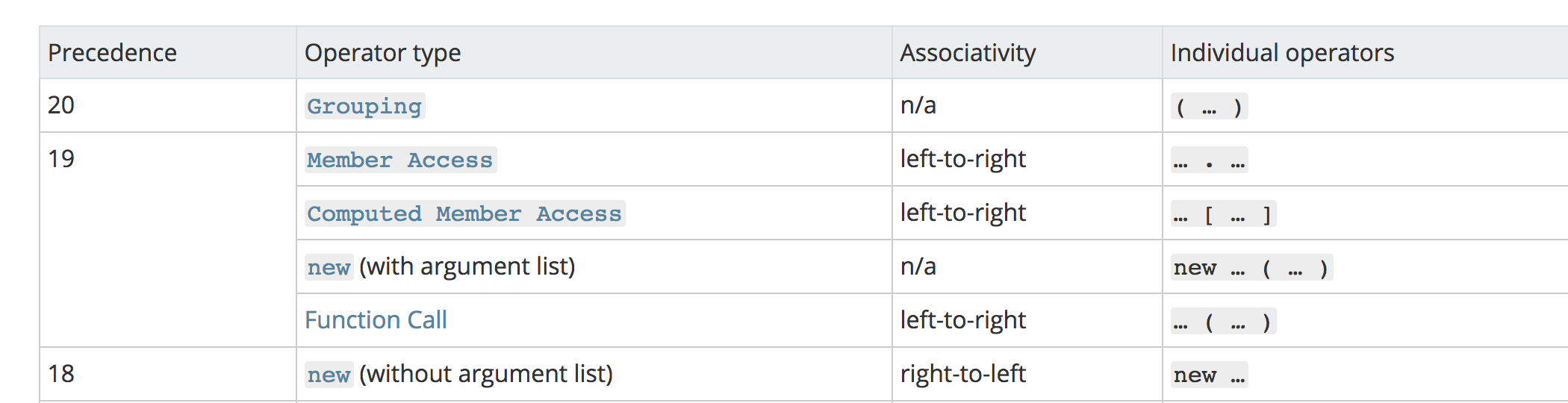
从上图可以看出,new Foo() 的优先级大于 new Foo ,所以对于上述代码来说可以这样划分执行顺序
new (Foo.getName()); (new Foo()).getName();
对于第一个函数来说,先执行了 Foo.getName() ,所以结果为 1;对于后者来说,先执行 new Foo() 产生了一个实例,然后通过原型链找到了 Foo 上的 getName 函数,所以结果为 2。
原型

每个函数都有 prototype 属性,除了 Function.prototype.bind(),该属性指向原型。
每个对象都有 __proto__ 属性,指向了创建该对象的构造函数的原型。其实这个属性指向了 [[prototype]],但是 [[prototype]] 是内部属性,我们并不能访问到,所以使用 proto 来访问。
对象可以通过 __proto__ 来寻找不属于该对象的属性,__proto__ 将对象连接起来组成了原型链。

